

Aggregation pipelines in Mongodb allow us to perform special operations on collections and documents stored in our database. They offer powerful and flexible ways to process, transform, and analyze data. Aggregation pipeline consists of a sequence of stages that perform specific operations on documents, each successive stage operates on the output of the previous stage, allowing for complex transformations.
What is a pipeline? A pipeline refers to a logical sequence of stages that process and transform data. Each stage utilizes a built-in aggregation operator like $set, $or, $sum, $match, $sort, etc. These operators perform various tasks such as filtering and grouping data in a collection, calculating values, and sorting results.
If you are familiar with the Linux pipe | operator, you can think of the aggregation pipeline as operating with a similar concept. Just as output from one command is passed as input to the next command, output is passed from one stage of the aggregation pipeline to the next until a finely processed document is obtained.
Aggregation pipelines are grouped into numerous stages and these stages have to be in the correct order (the order depends on the output you expect). The order of the stages is crucial as each stage processes the output of the one before it. Pipelines are also optimized to be efficient, improving performance compared to traditional find and modify operators. In addition to their efficiency, pipelines can handle various tasks including filtering, grouping, calculating, sorting of data, etc.
Here is an example using an aggregation pipeline.
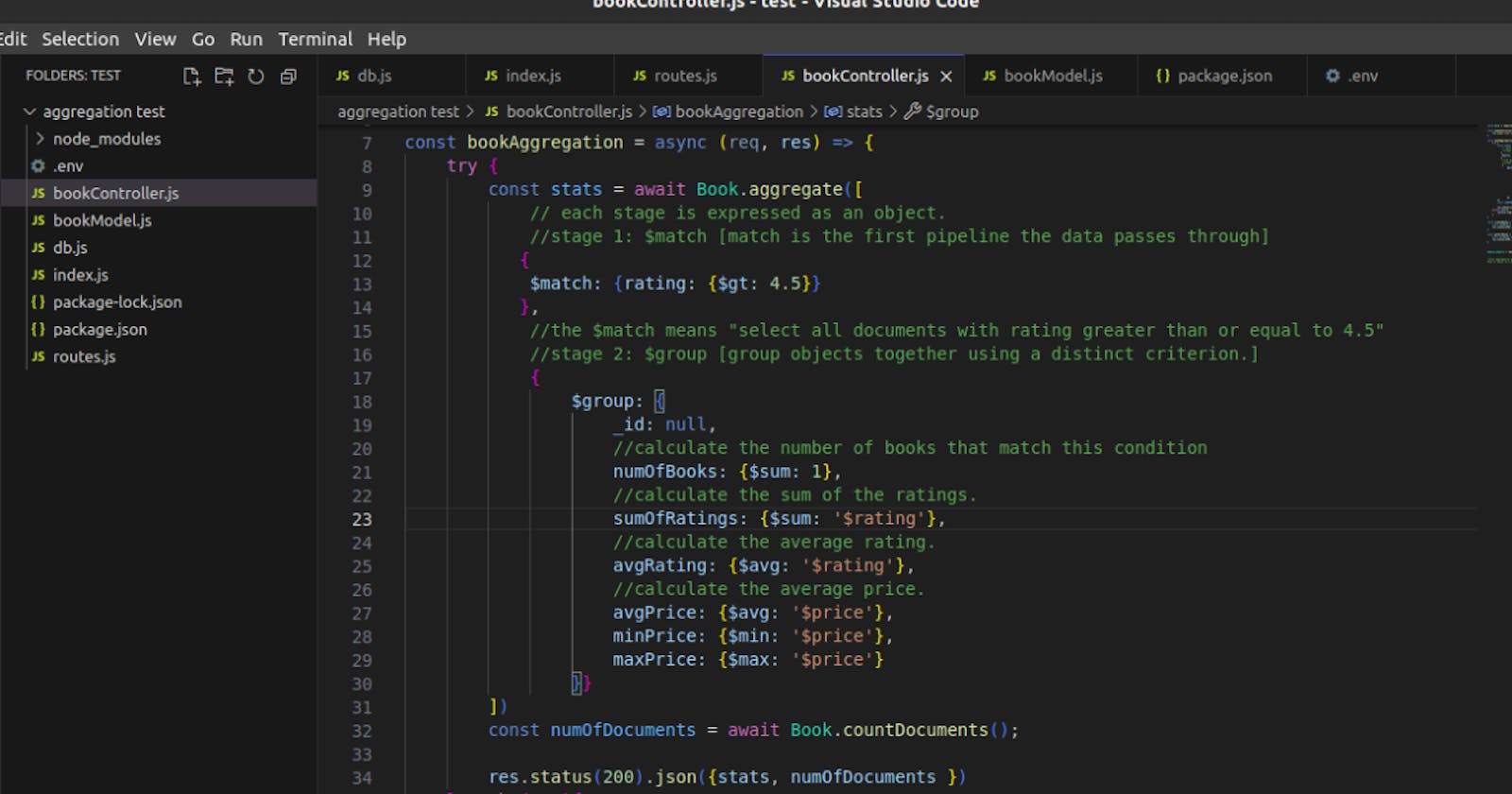
const bookAggregation = async (req, res) => {
try {
const stats = await Book.aggregate([
// each stage is expressed as an object.
//stage 1: $match [match is the first pipeline the data passes through]
{
$match: {rating: {$gt: 4.5}}
},
//the $match means "select all documents with rating greater than 4.5"
//stage 2: $group [group objects together using a distinct criterion.]
{
$group: {
_id: null,
//calculate the number of books that match this condition
numOfBooks: {$sum: 1},
//calculate the sum of the ratings.
sumOfRatings: {$sum: '$rating'},
//calculate the average rating.
avgRating: {$avg: '$rating'},
//calculate the average price.
avgPrice: {$avg: '$price'},
minPrice: {$min: '$price'},
maxPrice: {$max: '$price'}
}}
])
const numOfDocuments = await Book.countDocuments();
res.status(200).json({stats, numOfDocuments })
}catch (err){
console.log(err)
}
}
and this is the output:

To see the complete code sample, check out my GitHub repository here.
The example above is quite arbitrary, but it is just to give an insight into what you can do with aggregation pipelines in MongoDB.
Let me use this scenario. Assuming that you have/manage a hotel, you may want to find out the busiest business periods of the year. This insight will help you prepare for these times by knowing if you need to hire more staff during this period, optimize room prices, and also budget for a potential increase in operation costs.
In essence, the MongoDB aggregation pipeline empowers developers to efficiently process and analyze large datasets within the database itself, leading to cleaner code, improved performance, and deeper insights from their data.